Preparing your data for submission
Dandjoo currently accepts data in .csv, .xlsx, .xlsm or .shp formats with file sizes of up to 500MB. If you have data to submit that does not meet these requirements, please contact BIO, and one of our technical staff will be in touch to discuss how best we can ingest your data.
Dandjoo does not require you to provide your data in a template. However, if you have data in a spreadsheet with multiple worksheets, note that Dandjoo will only read the first worksheet in your file. If you want to submit data from other worksheets, you can either:
- aggregate your data on a single worksheet prior to submitting, if your column headers are consistent across all worksheets; or
- save each worksheet as a separate document, and submit them individually.
Dandjoo ingests data in various ways, depending on how the data was collected. Currently, it accepts three data types; species occurrence data, systematic survey data, and vegetation association data.

- Species Occurrence Data: Information about where a species was observed. Your dataset will contain a list of records by species, with information about the date and place each was observed. Each record in the dataset may refer to one individual of the species, or may include a count to indicate how many of the species were observed. The dataset may be generated from a systematic survey of sites, but the data will be arranged by species name.
- Systematic Survey Data: Information about observations of multiple species in a systematic survey. Your systematic survey data will contain one overarching project with one or more surveys, with each survey having one or more record of species observed.
- Vegetation Association Data: Information about vegetation associations. Your dataset will contain the polygons that define the boundaries of the vegetation associations.
Submitting species occurrence data
Submission requirements
Our submission tools include a quality assurance routine to validate the structure of species observation data files.
Please read the requirements below and check your file beforehand to ensure a quick and easy submission process.
- .csv, .xlsx, and .xlsm files are arranged in rows and columns, with the top row containing headers.
- The file contains an event date field.
- The file contains either latitude/longitude fields or eastings/northings/zone fields.
- The file contains a field or fields that identifies the organism (this should, at a minimum, provide genus and species; components of the organism’s scientific name may be in one field, or split across several fields).
- .shp files are zipped and include a.shp, .shx, and a .dbf.
- Column headers / field names are unique.
- Column headers / field names cannot be just a number. For instance, a column header of ‘1’ will not be accepted, but ‘one’ or ‘_1_’ will be.
- For .xlsx and .xlsm files, all data is contained on the first worksheet (additional worksheets will not be processed).
- Mandatory fields are populated for every record in the file, although it is acceptable to have blank cells in optional fields.
- Mandatory date and location fields contain an expected data type (Dandjoo recognises most common date formats and coordinate formats).
- The file contains at least one record (files that are blank other than a column headers will not be processed).
- The file does not contain special characters (files may only contain UTF-8 encoded characters).
If you attempt to upload a file that does not meet these requirements, you’ll receive a warning message.
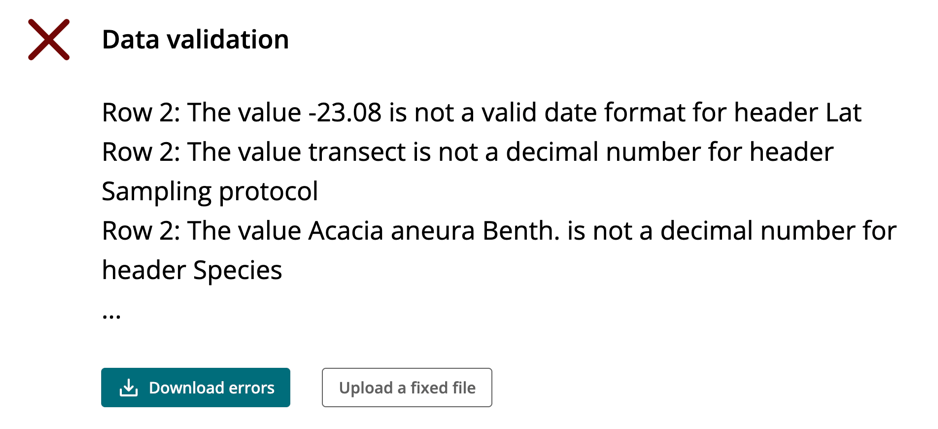
If you have difficulty in submitting your data as a result of the submission requirements, please contact BIO for support, and to let us know how the submission process can be improved in the future.
Mapping your data to a standard
You can use our self-service tools to ‘map’ species occurrence data to a selection of standard Darwin Core fields.
Resources
During submission, you will be asked to match headers of your submitted data to certain fields (for instance, ‘scientific name’ or ‘event date’). These fields are derived from internationally-recognised standards for biodiversity data and help us manage your data in a way that is consistent with FAIR data principles (Findable, Accessible, Interoperable and Reusable).
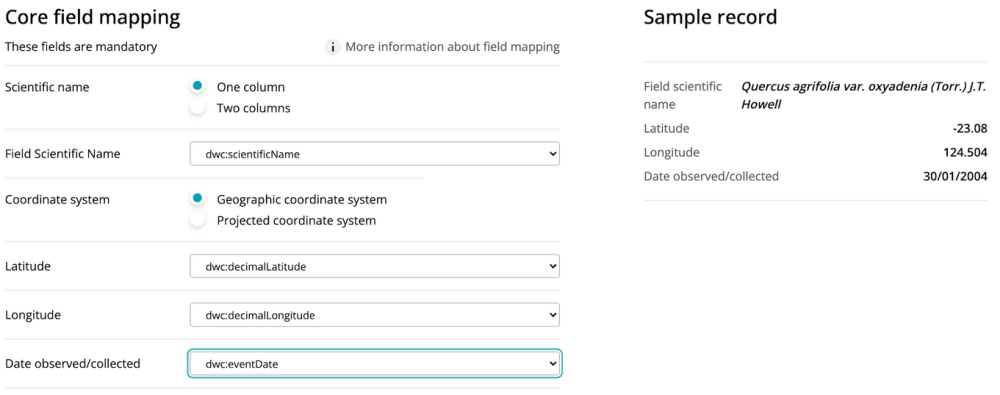
Some fields are mandatory - for example, we need to know the ‘what’, ‘when’ and ‘where’ of an observation to display it meaningfully. However we also offer submitters the opportunity to map data against a variety of optional fields derived from multiple international data standards (eg. Darwin Core). Mapping optional fields greatly enhances the value of your data for other users - for example, if you map the ‘habitat’ field to one of your variables your data can be combined and analysed with other datasets that also contain the same field. We highly encourage submitters to map optional fields, as it will help others understand and interpret the data.
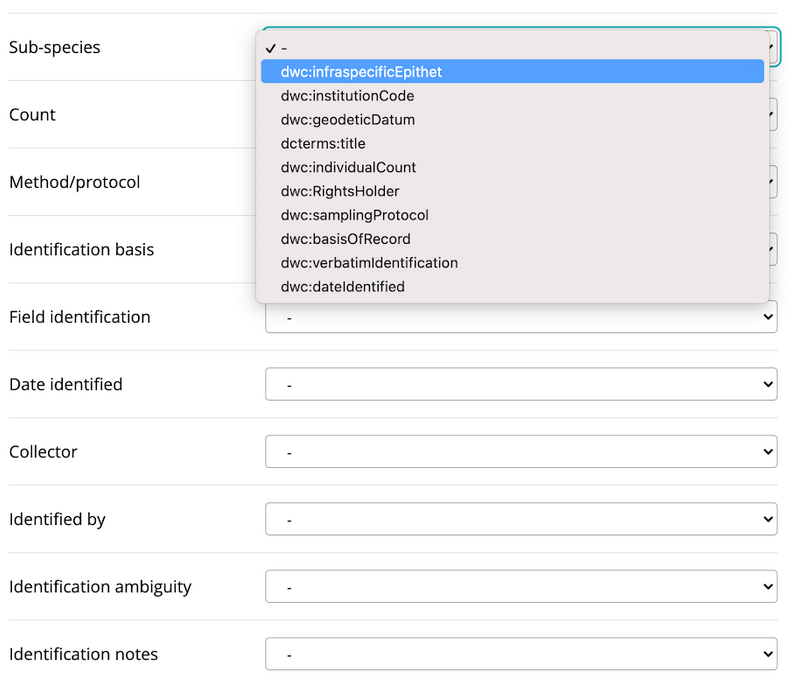
We believe that submitters are best placed to map their data, as they generally understand it best and are familiar with how it was collected. However, if you’re having difficulty mapping your data, don’t hesitate to ask us for help. BIO’s curatorial staff are familiar with data standard and the way in which other datasets have been mapped, and can assist you with submission and mapping.
Submitting systematic survey data and vegetation association data
If you submit systematic survey or vegetation association data, you will skip the self-service mapping stage, but the submission process is otherwise the same. BIO is exploring options to provide a mapping service for these data types in future releases, in addition to enhancing the way in which they are displayed for data users.
Chapter from guidelines, services and standards
Join the BIO newsletter and get updated first
Sign up for access to the latest developments at the Biodiversity Information Office, upcoming Dandjoo features, and our newest datasets.